I joined the Perceptions team in September 2024 to work on 2D & 3D LiDar object detection. Starting May 2024, I was appointed as the stream-4 Perceptions Lead :)
Intro to Perceptions Slide Deck
LiDar Object Detection
TIP
See Watonomous Cheatsheet for useful cmds.
See the WATO Stack for a high level infra overview.
PR branch here has demos of the LiDar node in action.
Perceptions Efforts
High level overview of WATO workflow
Here are my ideas for ideas on how we can make Perceptions CRACKED + things we should work on this term (Bold is for integration, the rest is for R&D)
- Downstream sensor fusion for tracked objects
- Pedestrian behaviour prediction
- Turn signal detection (I like this)
- Road marking detection
- Shared YoLo backbones
- Batched inference for YoLo models
- Build sensor mount
Questions for Eddy (Lead onboarding meeting)
- Leadership style?
- Where do priorities come from?
- Incoming co-op to perceptions questions
- Extra responsibilities as lead (meetings, keys, etc)
- Goal of S24
- Sensor rack + integration stuff?
Corresponding Notes from meeting
Self-driving means lots of things ;)
- Milestones from last term
- Camera, LiDar, MPC done (we got things done that directly touch the car)
- New milestones
- Split perceptions into R&D (new ideas etc.) & core (integration-side we need to get shit done)
- Once things that touch the car are done we want to do this:
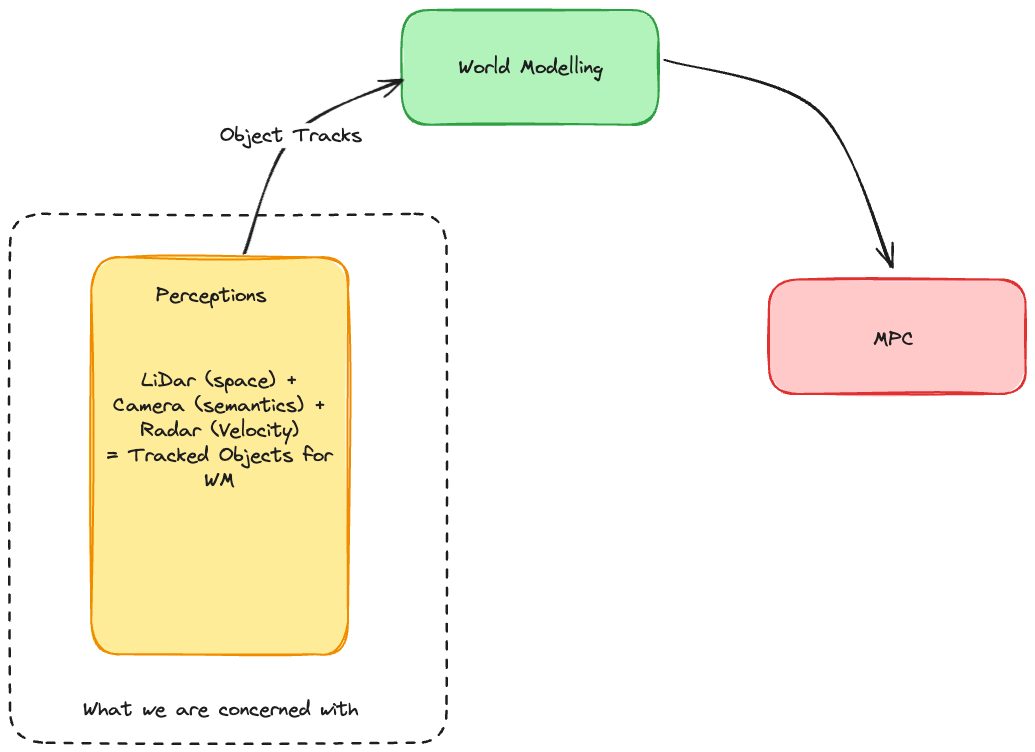
- Main objective: Tracking (Object Tracks)
- As opposed to just detecting objects in space we want to track OBJECTS and associate bounding boxes with objects not just take note of occupied positions (in addition to position we want velocity as well)
- We want to create tracked trajectories of objects from detections to send down-stream to WM
- We want to use each sensors strong suits to create these tracks
- LiDar: Spacial awareness
- Camera: Semantics
- Radar: Velocity
- Get Majority of tracks from camera, use the rest of the sensors for redundancy
- Sensor fusion is for building the tracks
- Look into AB3DMOT
- Sensor Rack
- Build this out!!!
- We should be involved since classical CV perceptions algorithms depend heavily on sensor extrinsics and intrinsics
- Support VP where needed
- Ideas
- Annotate shit (nope)
- Some type of simulation to get annotated data (sim2real problem)
- NeRF?
- We want to tune both configurations and models
- Both ROS stuff (things are overlapping well, timestamps have integrity) and ML models (fine tune models)
- AV Stack generalized: Perceptions, World Modelling, Action
- Perceptions: Senses
- World Modelling: Brain understanding the world and trying to predict the future
- MPC: What should you do based on prediction
- Output of perception is tacked objects for world modelling
Core Perceptions Stack
Perceptions Term Projects
- Monocular Depth Estimation
- Radar Velocity Detection
- 3D MOT
- Unifying Camera Detection
- Segformer Semantic Segmentation
- (LOW PRIORITY) Batched yolov8 inference
- (LOW PRIORITY) LiDAR Velocity Estimation
See Perceptions Backlog
Double check that the feed coming into the node is 30fps (for Lucas’s semantics)